圣诞节快到了,今年想给我的博客加一点小彩蛋,想来想去决定做一个下雪的背景。其实在 Web 中实现下雪效果并不是一件难事,我似乎十年前就见过一些有类似效果的博客。最常见的方案就是用 Canvas 实现一套粒子系统,这非常简单,性能和效果也够用。不过我这次想尝试一点不一样的东西,WebGPU 之前听说了很久,不过一直没有实际了解过,所以我打算试着用 WebGPU 实现这个下雪效果。
WebGPU 是什么
早期在 Web 中使用 GPU 渲染的唯一方式就是 WebGL(Canvas 的 2D context 也会使用 GPU 加速,不过由实现方决定),但 WebGL 基于的是 OpenGL ES 2.0,这是一套非常古老的 API,它的设计和开发体验早已不适合现代的硬件架构和应用。而 Vulkan、Metal 等新的图形 API 可以充分利用 CPU 资源,并且它们的设计使得驱动层很轻量,因此性能也会更好。
而 WebGPU 之于 Vulkan、Metal,就像 WebGL 之于 OpenGL,只是 WebGPU 在整体设计上更像是 Metal 的 Web 版本,API 方面更是接近 1:1 移植(有趣的是 Metal 4 还反向学习了一些 WebGPU 的设计)。Vulkan 可能由于接口非常底层,并不太适合在 Web 场景使用,所以 WebGPU 在设计时就没有太参考它。
与 WebGL 类似,WebGPU 也只是一套标准,它可以有很多套实现。例如 Chromium 中就使用了自家的 Dawn 作为实现,还有类似 wgpu 这样的库可以在浏览器环境以外使用。
虽然 WebGPU 在接口设计上与各大现代图形 API 很相似,接口实现基本也都是不同 backend 的适配器,但由于 WebGPU 使用了统一的 shader 语言 WGSL,所以 shader 翻译反而变成了实现中比较复杂的部分了。不过本文不打算深入讨论 WebGPU 实现相关的内容,主要只讨论一下开发体验。
Metal 101
上面说到 WebGPU 使用起来跟 Metal 非常像,那么对于我这种对 Metal 比较熟悉的开发者,上手门槛就很低了。我大概花了半天左右的时间了解了一下 API 差异,就可以着手开发博客的下雪效果了。
这里还是简单说下 Metal 的一些基础概念,方便对 GPU 编程不太了解的读者理解后文的内容。
在 Metal 中,我们主要会与下面这些对象打交道:
- Device - 表示一个 GPU 设备,用于创建资源、访问各种能力,可以作为一切的入口。
- Command / Queue - 用于表示提交给 GPU 的操作和提交到的队列。
- Pipeline - GPU 能够处理的各种管线,如渲染管线、计算管线等。
- Resources - GPU 执行操作时需要用到的各种资源,如 buffer、texture 等。
其中与 OpenGL 差异比较大的就是 Command Buffer 的概念了。由于 OpenGL 采用的是 freestanding 函数 + 状态机的模式,一个上下文只能由一个线程串行操作,这极大地削弱了多核 CPU 的优势。而 Metal 等现代图形 API 引入的 Command Buffer 和 Command Queue,则可以让我们在不同线程中向 GPU 提交操作。甚至可以使用 Command Queue 预先分配执行顺序,然后在不同线程中完成操作的配置。
接下来各种 Pipeline 就表示了 GPU 所提供的各项能力,例如最核心的渲染通常就是 Render Pipeline 完成的,一个 Render Pipeline 中会包含渲染所需的 Vertex Shader 和 Fragment Shader,以及一些 attachment 的配置。而 GPU 渲染的最小单元最常见的就是三角形,它的位置信息通常就会存储在 vertex buffer 里,这些就属于 GPU 操作所需的资源。
各种 shaders 可以让我们有机会通过代码定制渲染管线中的各个阶段,例如对顶点做一些变换,它们运行在 GPU 上。Metal 中的 shader 语言是类 C++ 的 MSL,它会在应用打包时预编译成字节码,从而一定程度上加速应用初始化。
一个渲染静态场景的应用通常会有以下的流程:
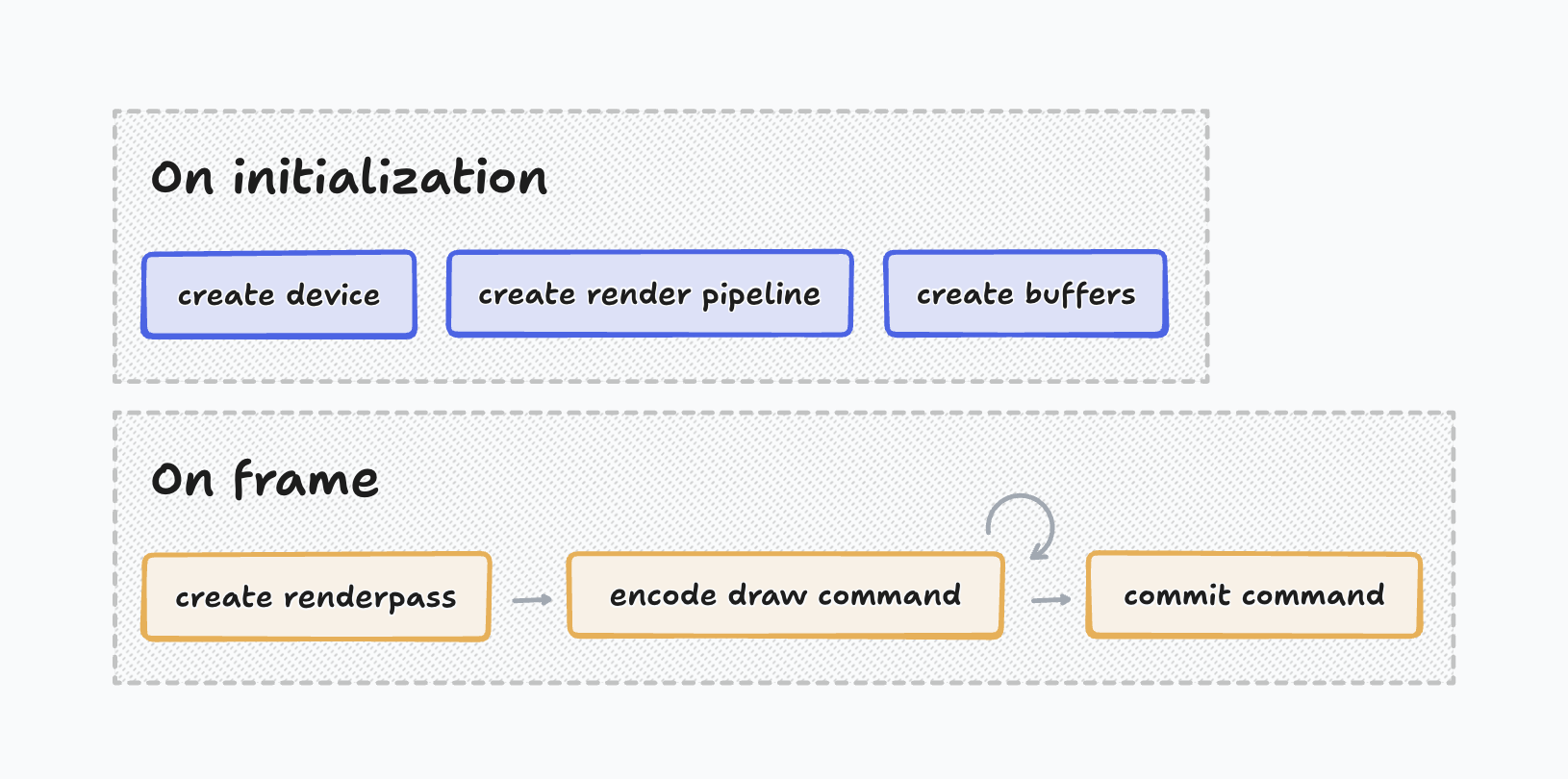
应用在初始化时会准备设备,创建渲染所需的管线、资源,这些在后续渲染中一般不会改变,可以复用。而渲染每一帧时,我们需要依次创建 Render Pass、创建渲染操作,然后提交渲染操作。一个 Render Pass 表示一次渲染,它指定了我们要将图形渲染到哪里。绘制三角形就是一个 Draw Command,它是一个可以被分配到 GPU 执行的最小操作,GPU 为了绘制三角形还会有一系列内部阶段(比如栅格化、着色等),不过对应用层不透明。
Metal 在顶点着色阶段接受的坐标是归一化的,因此一个三角形的顶点数据如下图表示:
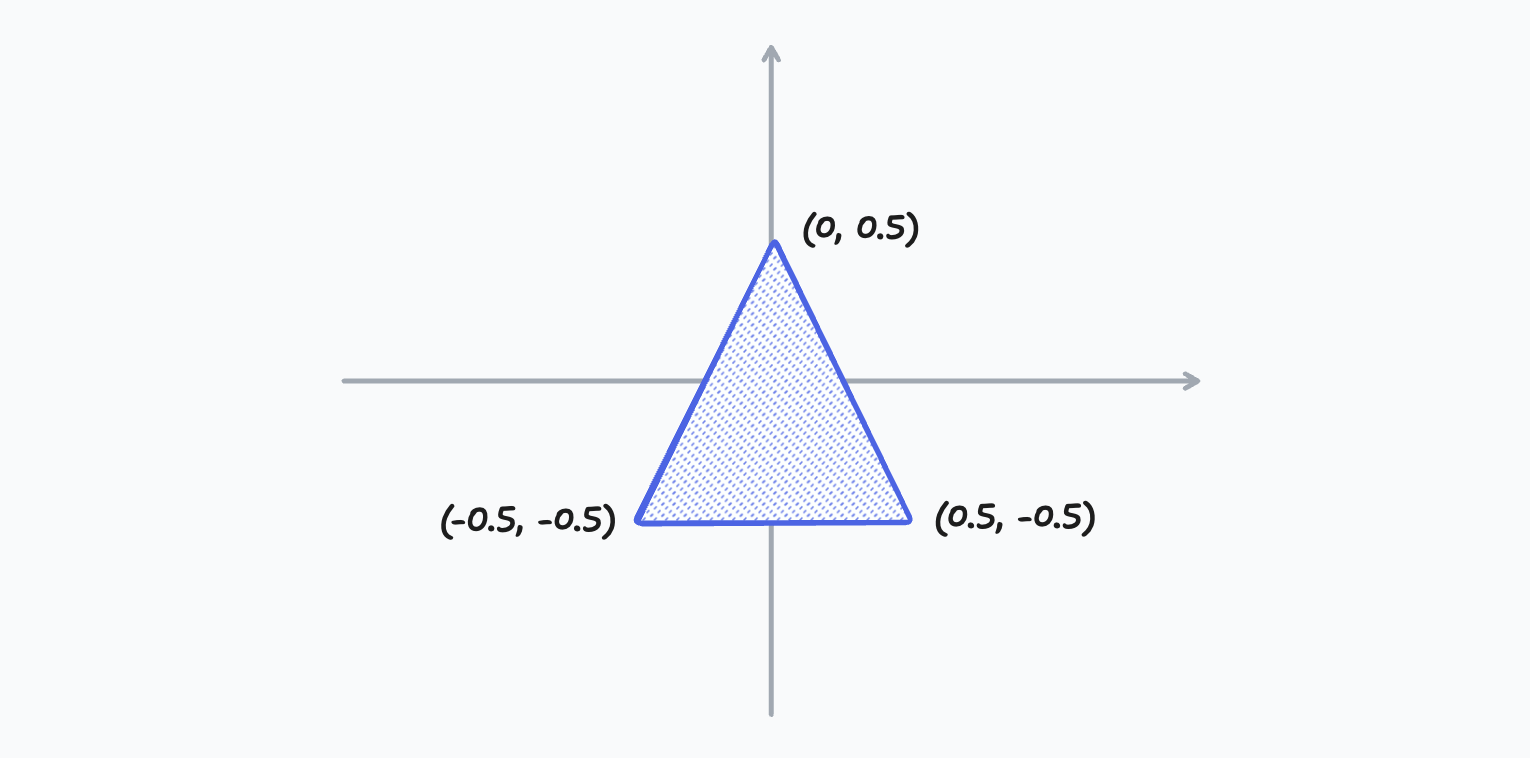
Vertex Shader 会处理一次绘制中的所有顶点,你可以在这个阶段对顶点做一些变换,从而实现不同的效果。Vertex Shader 处理之后的结果会经过栅格化,然后交给 Fragment Shader 来做最后的像素着色。这个阶段,Fragment Shader 拿到的是像素信息,这中间的插值就是 GPU 来做的。
对于绘制三角形的场景 shaders 就比较简单了,我们基本不需要什么额外处理:
vertex float4
vertexShader(uint vertexID [[vertex_id]],
constant simd::float3* vertexPositions)
{
return float4(vertexPositions[vertexID][0],
vertexPositions[vertexID][1],
vertexPositions[vertexID][2],
1.0f);
}
fragment float4 fragmentShader(float4 vertexOutPositions [[stage_in]]) {
return float4(1.0f);
}初识 WebGPU
上面是对 GPU 编程和 Metal 的一个非常简单的介绍,感兴趣的读者可以自行深入了解。回到 WebGPU 上,我们看一下 Metal 的概念在 WebGPU 中是如何体现的。首先是 Device,我们可以通过以下方式获得一个 GPUDevice 对象:
async function acquireGPUDevice() {
if (!navigator.gpu) {
return undefined;
}
const adapter = await navigator.gpu.requestAdapter({
featureLevel: "compatibility",
});
return await adapter?.requestDevice();
}WebGPU 支持访问多设备(如多张显卡),它们由 GPUAdapter 来表示,从一个 GPUAdapter 中我们又可以申请到一个 GPUDevice 对象,用于后续对该设备的操作。
想要将图像渲染到 Canvas 中,我们还需要一个上下文对象,用于获取绘制的目标 texture:
const context = canvas.getContext("webgpu");
context.configure({
device: theDevice,
format: navigator.gpu.getPreferredCanvasFormat(),
alphaMode: "premultiplied",
});初始化工作就是这么简单,后面我们就可以创建 pipelines 和准备各种资源了。
Bind Group
与 Metal 中松散设置 shaders 的各种资源不同,WebGPU 采用了 Bind Group 的方式来配置资源。我们可以一次创建,然后重复使用,这也一定程度提升了代码的执行效率(减少了校验和 JavaScript 的工作量)。例如我们的 vertex shader 中会使用到两个 buffer 资源,那我们就可以使用如下的代码预先创建好 bind group:
const renderBindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.VERTEX | GPUShaderStage.FRAGMENT,
buffer: {
type: "uniform",
},
},
{
binding: 1,
visibility: GPUShaderStage.VERTEX,
buffer: {
type: "read-only-storage",
},
},
],
});
const renderBindGroup = device.createBindGroup({
layout: renderBindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: uniformBuffer,
},
},
{
binding: 1,
resource: {
buffer: particleObjectBuffer,
},
},
],
});Bind Group 需要一个 layout 对象来描述结构,里面包含了各个资源的可见性、类型等信息。这个 layout 在特定情况下也可以自动生成,不过为了明确一些,我们这里就显式创建了。
在渲染时,我们调用 command encoder 的 setBindGroup 方法就可以直接将所有资源绑定到这个操作了,而不需要像 Metal 3 那样逐一设置。
WebGPU 里这种类似的优化还有 Render Bundle,同样可以节省 JavaScript 侧的工作量。
画一片雪花
我希望使用一个简单的圆形来表示一片雪花,通过 GPU 绘制一个圆形最 naïve 的方式就是用两个三角形画出一个正方形,然后再使用 Fragment Shader 渲染成圆形:
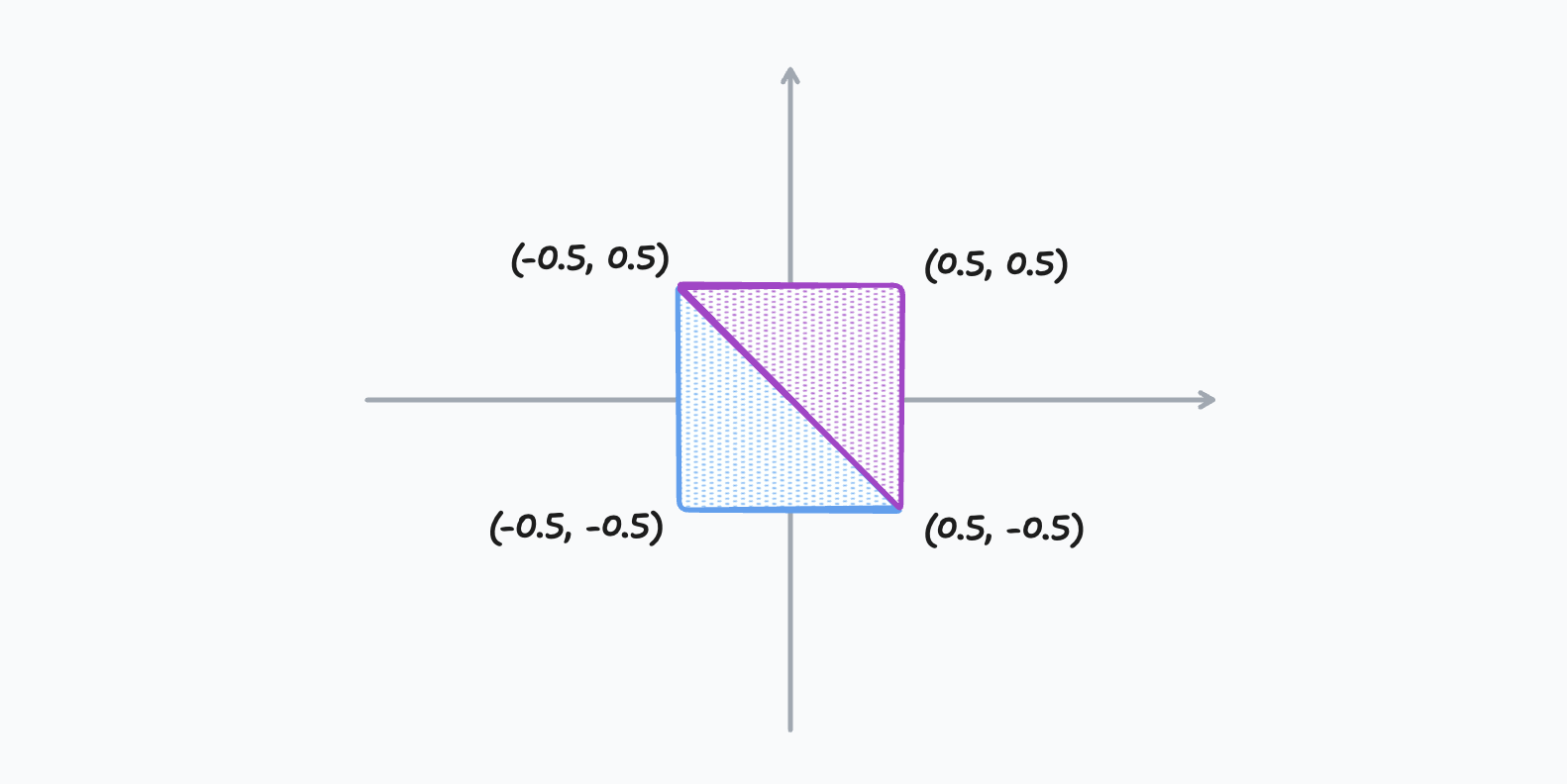
如大部分图形 API 一样,WebGPU 支持 strip 的方式绘制三角形,也就是相邻的每 3 个顶点构成一个三角形,这样我们就可以用 4 个顶点表示两个三角形了。同时,由于顶点是绝对静态的,我们甚至可以直接将顶点数据直接硬编码在下面 vertex shader 里:
struct QuadVertexOutput {
@builtin(position) position : vec4f,
@location(0) uv : vec2f,
}
@vertex
fn particleVertex(
@builtin(vertex_index) vertexIndex : u32
) -> QuadVertexOutput {
const vertices = array<vec2f, 4>(
vec2(-0.5, -0.5),
vec2(0.5, -0.5),
vec2(-0.5, 0.5),
vec2(0.5, 0.5)
);
let vertexPos = vertices[in.vertexIndex];
var out : QuadVertexOutput;
out.position = vertexPos;
out.uv = vertexPos * 2.0;
return out;
}渲染时调用 render pass encoder 的 draw(4, 1, 0 ,0) 就可以绘制出这一个正方形,其中 4 表示绘制操作涉及 4 个顶点,那么上面的 vertex shader 就会调用 4 次从而得到 4 个顶点。接下来我们就可以用下面的 fragment shader 把这个正方形渲染成一个圆形:
@fragment
fn particleFragment(in : QuadVertexOutput) -> @location(0) vec4f {
let dis = pow(distance(in.uv.xy, vec2f(0.0, 0.0)), 6.0);
let brightness = 1.0 - dis;
return vec4f(brightness);
}这里我们计算片段归一化坐标相距正方形中心点的距离,并且通过 pow 函数压缩一下边缘,然后将距离作为像素的亮度。这样一来,离中心点越远的像素,亮度就越低,从而就形成了一个有羽化效果的圆形:

而下雪,无非就是绘制超多的圆形,让它们从天而降地运动起来。这就是一个经典的粒子系统,我们要做的就是每帧更新粒子的状态(如位置、速度等),然后批量地将所有粒子绘制出来。
但我们有没有办法提高这一系列操作的性能?答案是肯定的。
使用 GPU 来计算粒子运动
在这个场景中,每个粒子的状态都是相互独立的,每一片雪花的运动互不影响。也就是说,我们完全可以并发地计算更新所有雪花粒子的状态。既然是并发,我们自然就应该想到 GPU,它最适合这种并发计算了。这恰恰是 WebGPU 相较于 WebGL 的优势,除了后者只能做的渲染操作以外,WebGPU 还可以做通用计算。那这里我们就来实践一下。
我们可以编写 Compute Shader 并用它创建一个 Compute Pipeline,然后就可以跟 Render Pipeline 一样将所需操作的资源绑定到上面。Render Pipeline 的最小单位是顶点,而 Compute Pipeline 的最小单位是 invocation。例如我们有 10 万个粒子,那么就应该对应 10 万次 invocations。若干个 invocations 又会打包成一个 workgroup,workgroups 之间相互独立,workgroups 内部的 invocations 则可以共享一些状态,也可以做一些同步操作。这些与 Metal 也都是一致的,只存在 API 命名上的区别。
为了让我们的 compute shader 和 vertex shader 可以共享粒子状态,我们在初始化时创建一个 buffer,并将它们设置到对应的 bind groups 中。后续我们就不会再在 CPU 中访问这个 buffer 的数据了,所有粒子状态将会完全在 GPU 内部处理。
const particleObjectBuffer = device.createBuffer({
// {
// position: vec2f,
// size: vec2f,
// velocity: vec2f,
// distance: f32,
// opacity: f32,
// spawned: i32,
// }
size: PARTICLE_COUNT * (3 * 2 * SIZEOF_F32 + 2 * SIZEOF_F32 + SIZEOF_I32),
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.STORAGE,
});创建好的 buffer 会用零填充,而我们的数据结构中有一个 spawned 字段可以用来标记这个粒子还没有被派生,在 compute shader 中就可以根据这个字段来初始化粒子的状态了。
控制粒子派生频率
由于我们的 compute pipeline 每一帧都会执行,每次执行会更新所有粒子。但在初始阶段,我们并不希望立刻派生所有粒子,我们需要控制派生的频率。这里我们有两种思路来实现这个效果:
- 通过一个链表维护所有待派生的粒子,并控制链表的长度。
- 维护一个共享的计数器,记录每次更新时已派生的粒子个数。
这两种方式都需要使用到一个特性 —— 原子操作。我这里使用了计数器,实现比较简单。
首先我增加了一个额外的 buffer 来维护每次更新的上下文,其中就包含了一个派生计数器:
struct SimulationContext {
time : f32,
timeDelta : f32,
randSeed : f32,
particlesToSpawn : atomic<i32>,
}更新时判断是否需要派生新粒子,如果需要则先判断计数器,只有数量满足才执行派生操作:
@binding(1) @group(0) var<storage, read_write> writableParticles : array<Particle>;
@binding(2) @group(0) var<storage, read_write> simulationCtx : SimulationContext;
@compute @workgroup_size(64)
fn updateParticles(@builtin(global_invocation_id) globalInvocationId : vec3u) {
var particle = writableParticles[globalInvocationId.x];
if (particle.spawned == 0 || particle.position.y > uniforms.viewportSize.y) {
if (atomicSub(&simulationCtx.particlesToSpawn, 1) > 0) {
// Spawn the particle...
}
}
// ...
}atomicSub 会先执行减法操作,然后返回操作前的值。这个过程是原子的,两次操作的返回值一定是不重复且递减的。
这样一来,每次更新粒子前设置一下 particlesToSpawn 的值,就可以控制这次更新所能派生的最大粒子数了。
添加一点随机性
我们的雪花粒子需要多元化,有大的有小的,有近的有远的,初始速度也不能一样。这就需要用到随机函数了。
在 CPU 计算中,获取随机数通常可以采用基于时间的伪随机数,和基于各种熵源的真随机数。但 GPU 在执行 shader 时获取的只能是固定的 buffer,时间、种子都只能由 CPU 传递。一般来说,开发者都会使用一个相对时间来计算随机数,尤其是在一些生成式效果中,两帧画面需要有连续性。但我们这里的随机数只用在了粒子派生上,这是一个离散的计算,因此我们可以直接在 JavaScript 中通过 Math.random() 获取一个随机数作为种子,然后衍生计算出一系列随机数。
我在上面的 SimulationContext 中添加了一个 randSeed 字段,然后在 shader 中添加了一个用于获取随机数的函数:
struct Pcg32RandomState {
state : u32,
}
var<private> randState : Pcg32RandomState;
fn initRand(invocationId : u32, seed : f32) {
randState.state = invocationId * 1664525u + u32(seed * 1664525.0);
}
fn rand() -> f32 {
let state = randState.state * 747796405u + 2891336453u;
let word = ((state >> ((state >> 28u) + 4u)) ^ state) * 277803737u;
randState.state = (word >> 22u) ^ word;
return f32(randState.state) / 4294967296.0;
}这里使用到了一个 Pcg32 的算法,在每次计算调用的最开始,首先调用 initRand() 初始化随机状态,然后每次调用 rand() 就可以得到一个不同的随机数了。这里同时使用了 global_invocation_id 和 randState 作为墒源,从而保证了所有粒子即使在同一帧都能得到不一样的随机数分布。
使性能更进一步
效果实现完了,一切看起来都不错。但我发现有一个小瑕疵,那就是在页面间导航时,动画可能会卡顿一下。通过 profile 得知是 React 渲染的 commit phase 耗时较长,使得整体耗时超过一帧的时间。那有没有办法让我们 renderer 的逻辑与 React 相关逻辑并发执行呢?
现在大部分浏览器都支持了 OffscreenCanvas 的特性,可以在 worker 中进行渲染工作。WebGPU 同样也支持在 worker 中使用,所以我们完全可以把整个效果的渲染都转移到 worker 中。
我原本的 renderer 大致结构如下:
export class Renderer {
// ...
constructor(context: GPUCanvasContext, device: GPUDevice) {
// ...
}
// ...
}构造时只需要一个 Canvas 的 context 和一个 GPUDevice 即可,因此这部分代码可以直接运行在 worker 环境中,无需任何改动。
Worker 顶层代码会获取 GPUDevice,并在成功后向主线程发送一个消息:
acquireGPUDevice().then((maybeDevice) => {
if (!maybeDevice) {
return;
}
const device = maybeDevice;
// ...
self.postMessage({ type: "ready" });
}主线程这边在 worker 准备就绪后创建 Canvas 并通过 transferControlToOffscreen 获取离屏上下文,然后也以消息的形式发回给 worker 即可:
useLayoutEffect(() => {
if (!ref.current) return () => {};
const canvas = document.createElement("canvas");
canvas.style.width = "100%";
canvas.style.height = "100%";
const offscreenCanvas = canvas.transferControlToOffscreen();
worker.postMessage(
{ type: "attach", canvas: offscreenCanvas } satisfies WorkerMessage,
[offscreenCanvas],
);
ref.current.appendChild(canvas);
// ...
return () => {
// ...
canvas.remove();
worker.postMessage({ type: "detach" } satisfies WorkerMessage);
};
}, [ref, worker]);现在,我们的动画就完全跑在一个独立的线程中了。而且得益于主流浏览器都具有单独的合成器进程,主线程 UI 无论多卡顿都不会影响到背景动画。
现在很多网页中都会有一些复杂的动画效果,如果这些效果并没有太多交互元素,其实都可以通过这种方式来优化性能,相信对网页整体流畅性会有很大的提升。
结语
本文算是自己第一次尝试 WebGPU 的一个小记,里面具体的实现细节就不展开说了,有兴趣的朋友可以直接到我的博客仓库里看源码。
不管是 Metal 还是 WebGPU,其实都是比较底层的技术。作为应用开发者,我们一般都会基于上层框架来开发业务。Web 中常用的 Three.js 和 Babylon.js 现在也支持 WebGPU 作为后端实现,相信随着浏览器新版本的普及,越来越多的网站也可以从中受益。一定程度上说,它可能也会成为浏览器端侧 LLM 的技术基石,就让我们期待一下吧。